1. Regressions for Hypothesis Testing
Vocabulary
“Linear Model”, “Linear Regression”, “Multiple Regression” or simply “Regression” are all referring to the same model: The General Linear Model.
It contains:
- 1 continuous Outcome/Dependent Variable
- 1 or + categorical or continuous Predictor/Independent Variables
- Made of Main and/or Interaction Effects
\[Y = b_{0} + b_{1}\,Predictor\,1 + b_{2}\,Predictor\,2+ ... + b_{n}\,Predictor\,n + e\]
A Linear Regression is used to test all the hypotheses at once and to calculate the predictors’ estimate.
General Linear Model Everywhere
Most of the common statistical models (t-test, correlation, ANOVA; chi-square, etc.) are special cases of linear models.
This beautiful simplicity means that there is less to learn. In particular, it all comes down to \(y = ax + b\) which most students know from secondary school.
Unfortunately, stats intro courses are usually taught as if each test is an independent tool, needlessly making life more complicated for students and teachers alike.
Here, only one test is taught to rule them all: the General Linear Model (GLM).
Applied Example
Imagine the following case study…
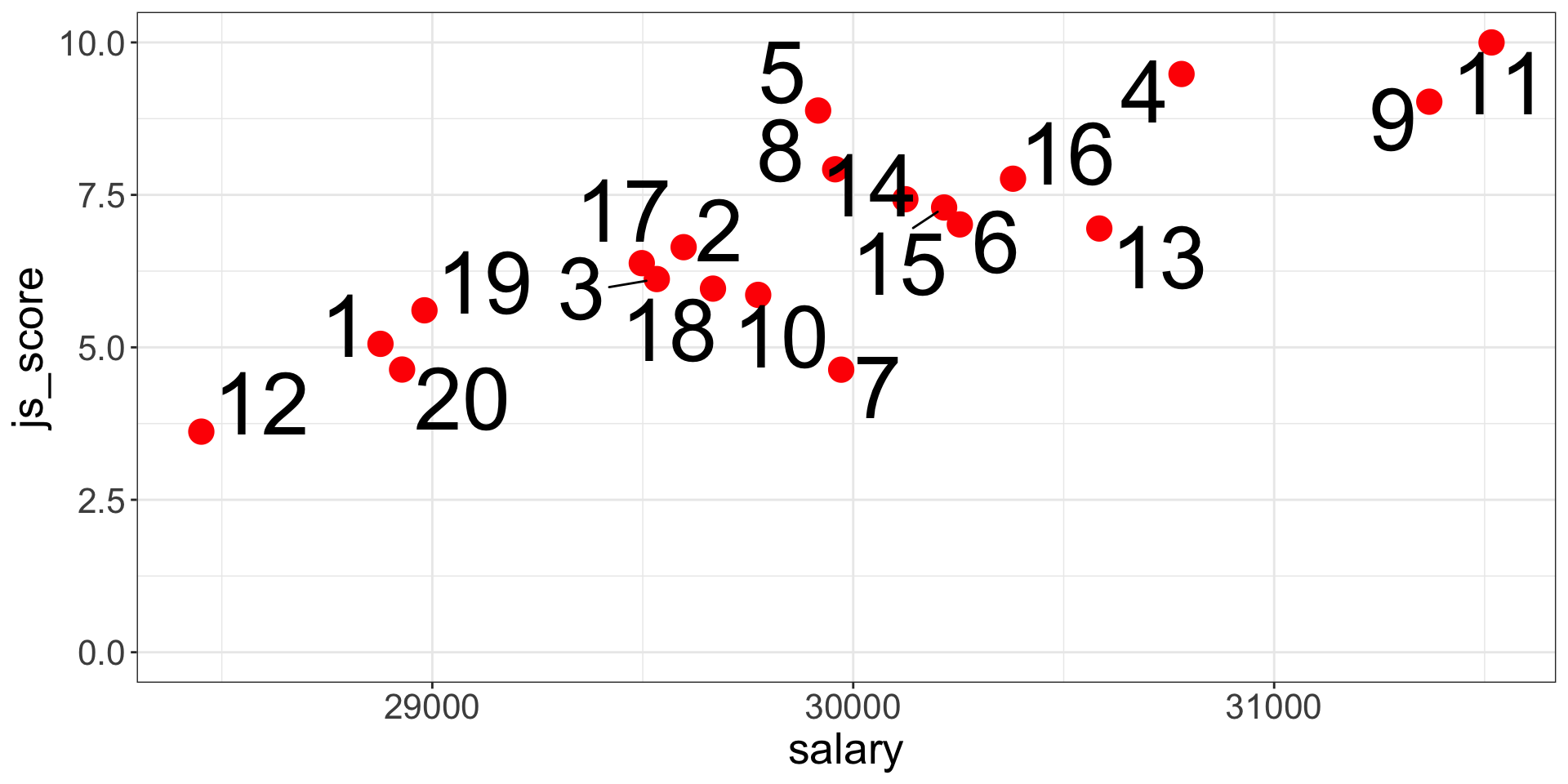
The CEO of Organisation Beta has problems with the well-being of employees and wants to investigate the relationship between Job Satisfaction (js_score), salary and performance (perf).
- \(H_{a1}\): \(js\_score\) increases when \(salary\) increases
- \(H_{a2}\): \(js\_score\) increases when \(perf\) increases
- \(H_{a3}\): The effect of \(salary\) on \(js\_score\) increases when \(perf\) increases
The corresponding model is:
\[js\_score_i = b_{0} + b_{1}\,salary_i + b_{2}\,perf_i + b_{3}\,salary*perf_i + e_i\]
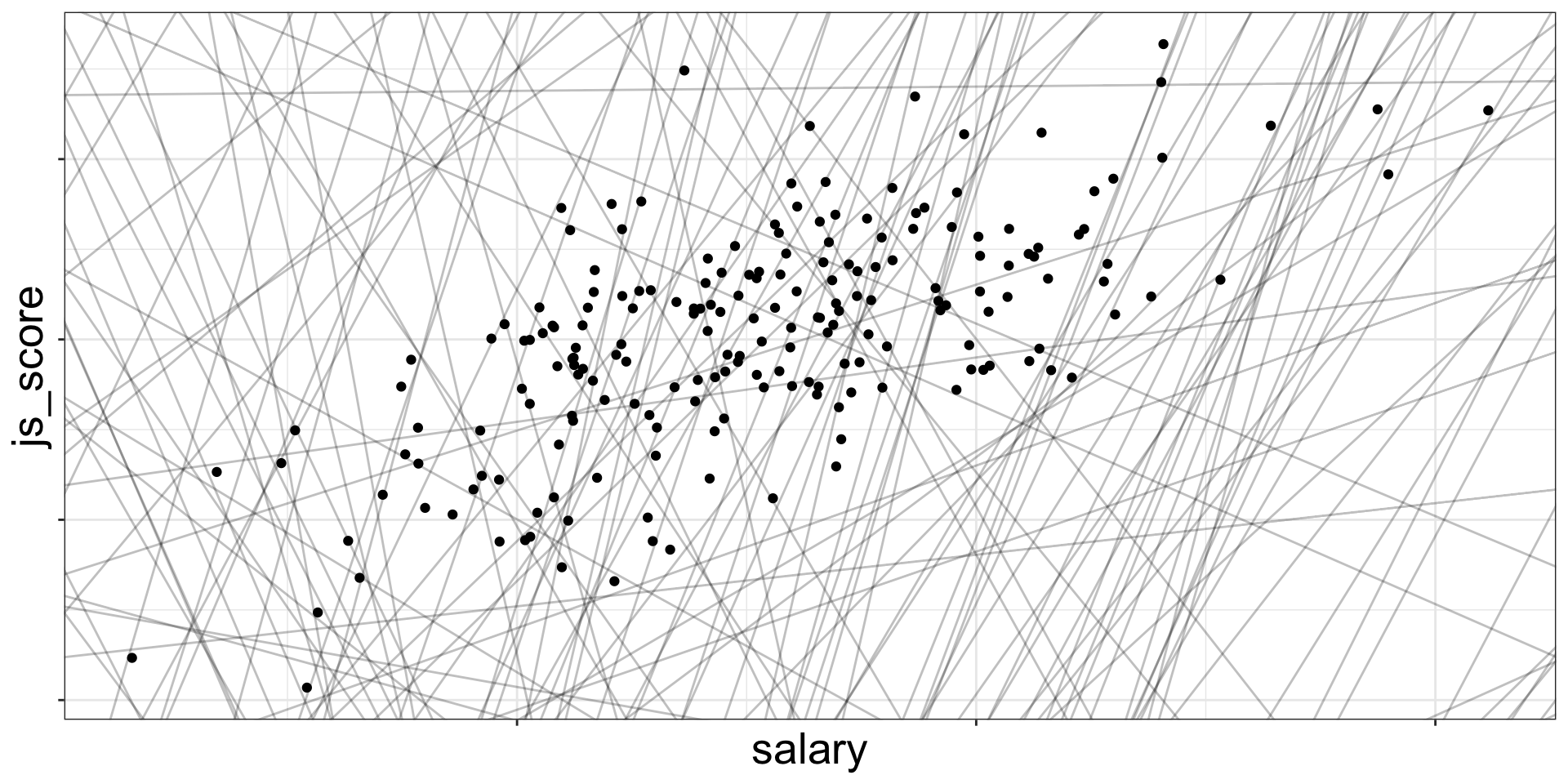
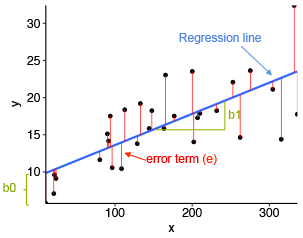
Finding the Best Line
Draw all the possible lines on the frame. The best line, also called best fit, is the one which has the lowest amount or error.
![]()
There are 200 models on this plot, but a lot are really bad! We need to find the good models by making precise our intuition that a good model is “close” to the data.
Finding the Best Line
To find the best line (i.e., the best model), we need a way to quantify the distance between the data and a model.
Then we can fit the model by finding the value of \(b_0\) and \(b_1\) that generate the model with the smallest distance from this data.
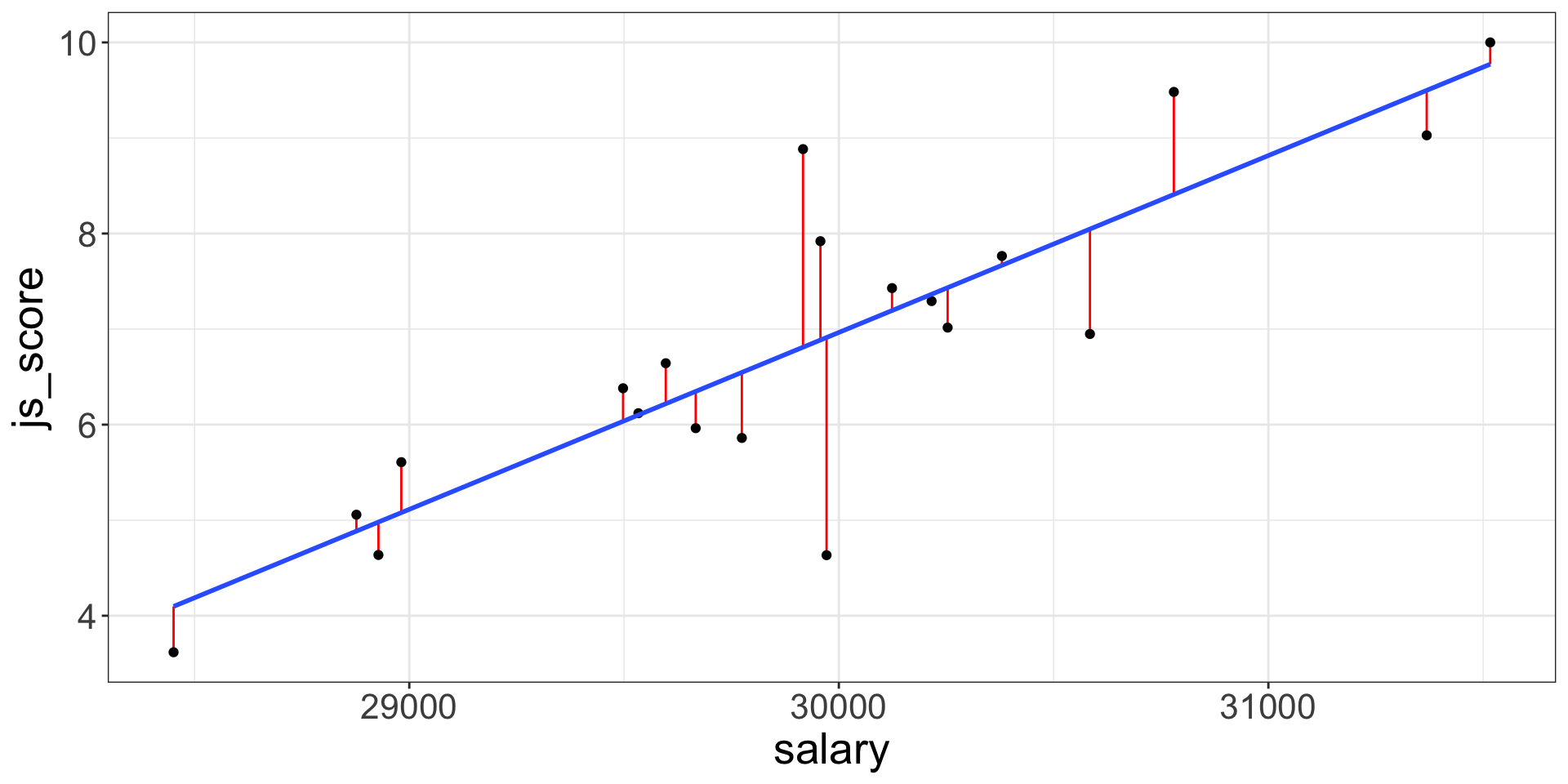
Best Model, Lowest Error
For each point this specific prediction error is called Residual \(e_i\) where \(i\) is a specific observation (e.g., employee here).
The error of the model is the sum of the prediction error for each point (distance between actual value and predicted value).
![]()
Best Model, Lowest Error
The line which obtains the lowest error, has the smallest residuals. This line is chosen by the linear regression.
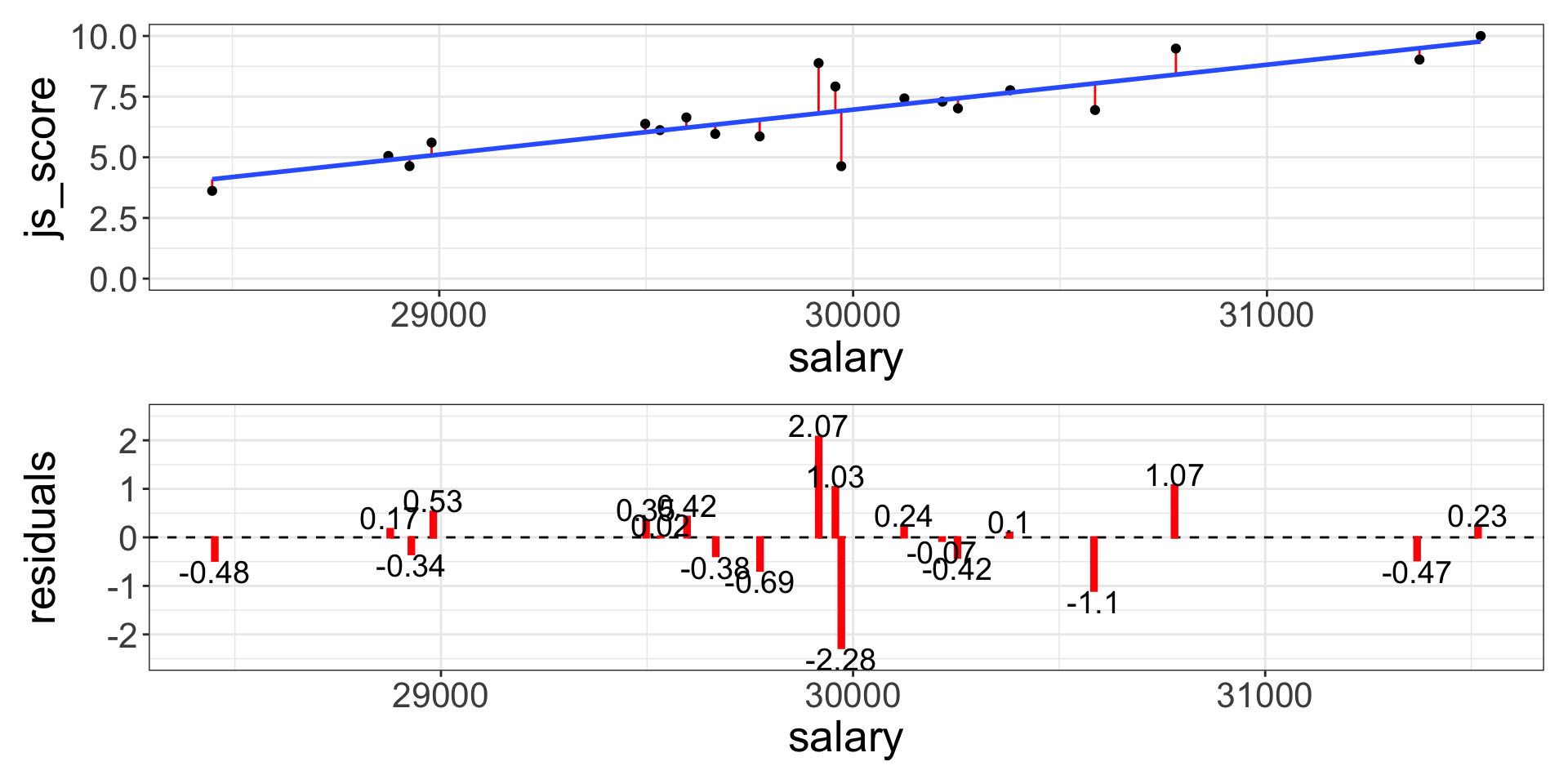
One common way to do this in statistics to use the “Mean-Square Error” (aka \(MSE\)) or the “Root-Mean-Square Error” (aka \(RMSE\)). We compute the difference between actual and predicted values, square them, sum them and divide them by \(n\) observations (and the take the square root of them for the \(RMSE\)).
\[MSE = \frac{\sum_{i=1}^{N}(y\,predicted_{i} - y\,actual_{i})^{2}}{N}\]
\[RMSE = \sqrt{\frac{\sum_{i=1}^{N}(y\,predicted_{i} - y\,actual_{i})^{2}}{N}}\]
The (Root-)Mean-Square Error
![]()
These calculations have lots of appealing mathematical properties, which we are not going to talk about here. You will just have to take my word for it!
Analysis of the Estimate
Once the best line is found, each estimate of the tested equation is calculated by a software (i.e., \(b_0, b_1, ..., b_n\)).
- \(b_0\) is the intercept and has no interest for hypothesis testing
- \(b_1, ..., b_n\) are predictors’ effect estimate and each of them is used to test an hypothesis
The predictors’ effect estimate \(b_1, ..., b_n\) are the value of the slope of the best line.
It indicates how many units of the outcome variable increases/decreases/changes when the predictor increases by 1 unit
Technically, \(b\) is a weight or multiplier applied to the Predictor’s values to obtain the Outcome’s expected values
Analysis of the Estimate
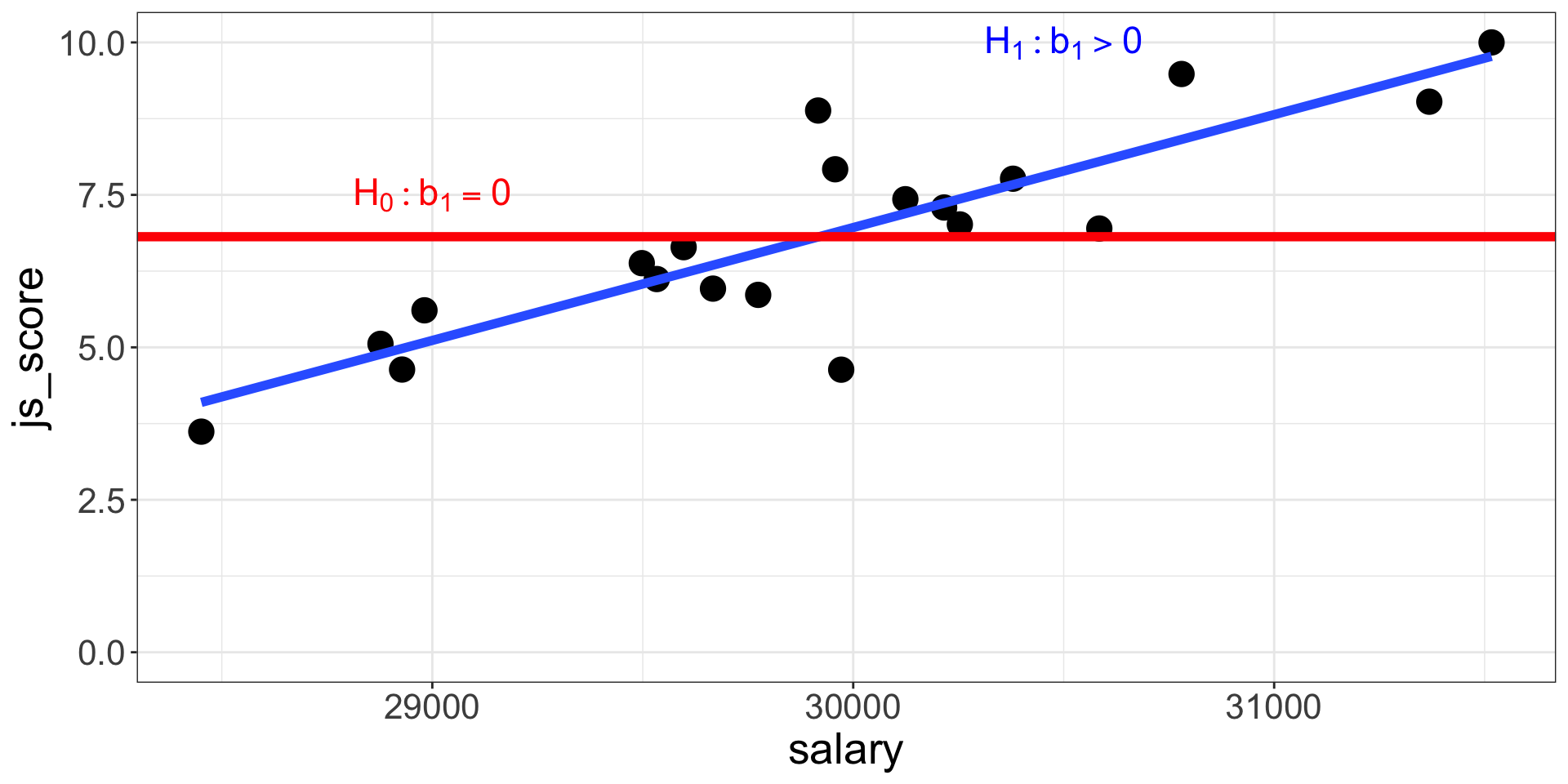
- If \(b_1, ..., b_n = 0\), then:
- The regression line is horizontal (no slope)
- When the Predictor increases by 1 unit, the Outcome variable does not change
- The null hypothesis is not rejected
- On the contrary, if \(b_1, ..., b_n > 0\,or < 0\), then:
- The regression line is positive (slope up) or negative (slope down)
- When the Predictor increases by 1 unit, the Outcome variable increases/decreases by \(b\)
- The alternative hypothesis considered as plausible
Significance of Effect’s Estimate
The statistical significance of an effect estimate depends on the strength of the relationship and on the sample size:
- An estimate of \(b_1 = 0.02\) can be very small but still significantly different from \(b_1 = 0\)
- Whereas an estimate of \(b_1 = 0.35\) can be stronger but in fact not significantly different from \(b_1 = 0\)
The significance is the probability to obtain your results with your sample in the null hypothesis scenario:
- Also called \(p\)-value
- Is between 0% and 100% which corresponds to a value between 0.0 and 1.0
If the \(p\)-value is lower to 5% or 0.05, then the probability to obtain your results in the null hypothesis scenario is low enough to say that the null hypothesis scenario is rejected and there must be a link between the variables.
Remember that the \(p\)-value is the probability of the data given the null hypothesis: \(P(data|H_0)\).
Estimating Regression’s Coefficients
As previously indicated, you will not have to calculate all the possible lines in your data to find the best fit, a software will do it for you:
- JAMOVI, JASP or SPSS have a Graphic User Interface
- R, Python or Julia are language based and have no interface
![]()
Estimating Regression’s Coefficients
The output of any software is two tables:
- Model Fit Measure Table
- Model Coefficients Table
The Model Fit Measure table tests the prediction accuracy of your overall model (all predictors taken into account).
The Model Coefficients table provide an estimate to each predictor \(b_1, ..., b_n\) (as well as the intercept \(b_0\)). the value of the estimate is statistically tested with a \(p\)-value to see if it is statistically different from 0 (null hypothesis). Therefore, this table is used to test each hypotheses separately.
JAMOVI: Stats. Open. Now.
Jamovi is a statistical spreadsheet software designed to be easy to use. Jamovi is a compelling alternative to costly statistical products such as SPSS, SAS and JMP to cite a few.
Jamovi will always be free and open because Jamovi is made by the scientific community, for the scientific community.
- It can be downloaded from its website https://www.jamovi.org/
- It can also be used without installation, in a web browser, https://cloud.jamovi.org/ for online demo but this demo undergoes periods of downtime, and may cease functioning (without warning) at any time.
JAMOVI: Stats. Open. Now.
![]()
JAMOVI GUI
![]()
Anatomy of JAMOVI
1. Different symbols for variable types
![]()
2. Distinction between Factors and Covariates:
- A Factor is a predictor of type categorical (nominal or ordinal)
- A Covariate is a predictor of type continuous
Expected variable type is displayed in bottom right corner of boxes
3. Customise your analysis by unfolding optional boxes
4. Two linear regression tables by default:
- Model Fit Measures
- Model Coefficients
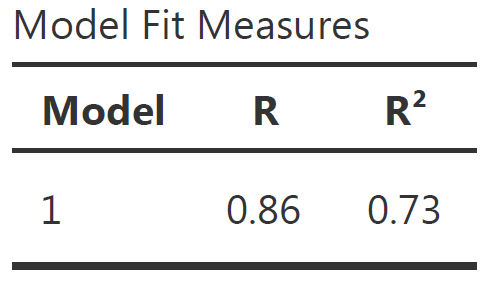
Reporting the Model Fit Measure Table
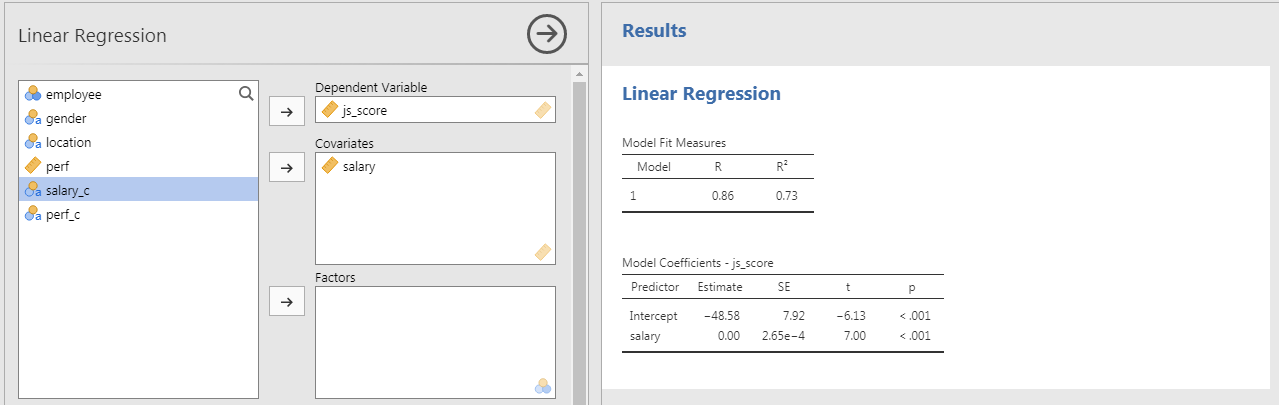
The Model Fit Measure table tests the prediction accuracy of your overall model (all predictors taken into account).
\(Model_{a}: js\_score = b_{0} + b_{1}\;salary + e\;vs.\; Model_{0}: js\_score = b_{0} + e\)
![]()
Default Columns:
- The Model column indicate the reference of the model in case you want to compare multiple models
- \(R\) is the correlation between the outcome variable and all predictors taken into account (i.e., the closer to 1 or -1 the better, however in social science models with more that 0.2 or less than -0.2 are already excellent)
- \(R^2\) is the % of variance from the outcome explained by the model (e.g., \(R^2 = 0.73\) means the model explains 73% of the variance of the outcome variable). \(R^2\) is also called Coefficient of Determination
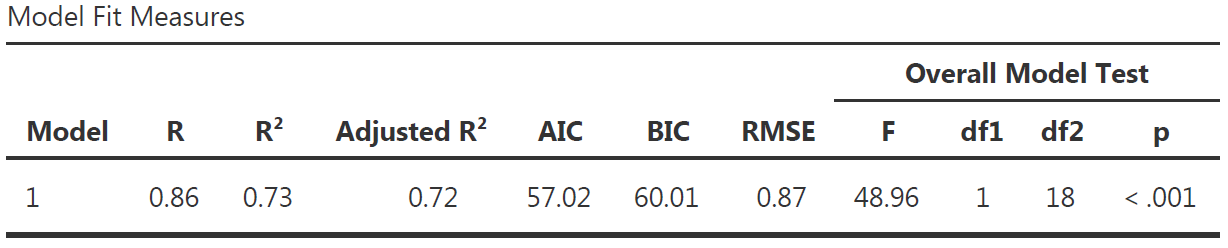
More Model Fit Measures
![]()
- \(Adjusted\,R^2\) is a more conservative version of \(R^2\), usually not reported
- \(AIC\), \(BIC\) and \(RMSE\) are useful to compare multiple models, the lower the better
- Overall Model F Test is the statistical test to show that your model have significantly better predictions than a model without any predictor.
- \(F\) is the value of the statistical test comparing the results obtained with this sample using the full model with the results obtained with this sample using a model only with the intercept (i.e., \(H_0\))
- \(df1\) is the degree of freedom “between group”, its value corresponds to the amount of predictor in your model: \(df1 = K\) (this is the easy explanation, see more details page 398 of “Learning Statistics with JAMOVI”)
- \(df2\) is the degree of freedom “within group”, its value corresponds to the amount of observation minus number of parameters minus 1: \(df2 = N - K - 1\).
- \(p\) is the p-value, i.e the probability to obtain our prediction with our sample in the null hypothesis scenario (i.e., \(p = P(data|H_0)\))
Communicate Model Fit Measures
To communicate results about a model, APA style is a good guide. Report the following values using the Model Fit Measure table with all options:
\[R^2 = value_{R^2}, F(value_{df1},value_{df2}) = value_{F}, p = value_{p}\]
Model Fit Measure table with all options from our example and corresponding sentence to include in the result section:
![]()
The predictions from the alternative model (i.e., with our predictors) are significantly better than the predictions from a null model (\(R^2 = .73\), \(F(1, 18) = 48.96\), \(p < .001\)).
- If the value in the table is \(< 0.001\), then write \(p < 0.001\) in the text
- Or else, write \(p = value_p\) (e.g., \(p = 0.58\)) but never \(p =< 0.001\)
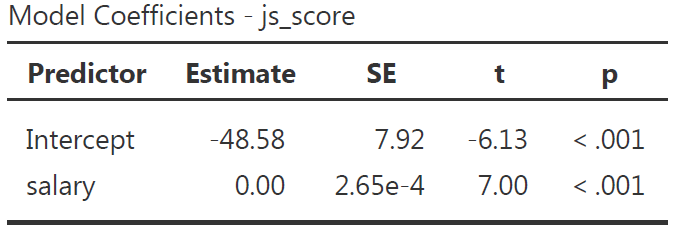
Reporting the Model Coefficients Table
The Model Coefficients table provide an estimate to each predictor \(b_1, ..., b_n\) (as well as the intercept \(b_0\)). the value of the estimate is statistically tested with a \(p\)-value to see if it is statistically different from 0 (null hypothesis).
![]()
Default Columns:
- Predictor is the list of variables associated to parameters in your model (main and interaction) which includes the intercept
- Estimate is the non-standardized relationship estimate of the best prediction line (expressed in the unit of the variable)
- SE is the Standard Error and indicate how spread are the values around the estimate
- \(t\) is the value of the statistical test comparing the estimate obtained with this sample with an estimate of 0 (i.e., \(H_0\))
- \(p\) is the p-value, i.e the probability to obtain our prediction with our sample in the null hypothesis scenario
More Model Coefficients
![]()
- Omnibus ANOVA Test is an alternative way to test model’s coefficient but use only for a categorical predictor with more than 2 modalities
- Estimate Confidence Interval defines the limits of the range where Estimate are still possible to be in given the sample size
- Standardize Estimate indicates the strength and direction of the relationship in term of correlation
More Model Coefficients
![]()
Note that in our example, because there is only one predictor:
- The Standardize Estimate is the correlation
- The \(F\)-test in the Model Fit Measure table is the same as the \(F\)-test in the Omnibus ANOVA Test
- The \(p\)-value in the Model Fit Measure table is the same as the one in the Omnibus ANOVA Test and in the Model Coefficient table
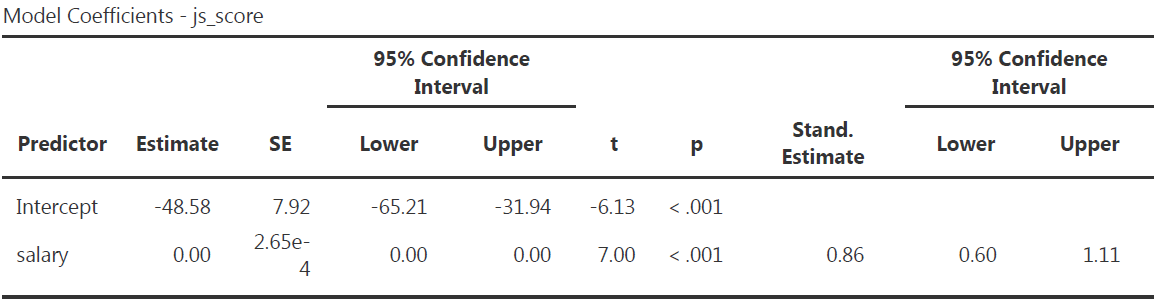
Communicate Model Coefficients
Report the following values using the Model Coefficients table with all options:
\[b = value_b, 95\% CI [value_{lower\,CI}, value_{upper\,CI}], t(df_2) = value_t, p = value_{p}\]
Model Coefficients table with all options from our example and corresponding sentence to include in the result section:
![]()
The effect of \(salary\) on \(js\_score\) is statistically significant, therefore \(H_0\) can be rejected (** \(b = 0.00\), 95% CI \([0.00, 0.00]\), \(t(18) = 7.00\), \(p < .001\)**).
\(p\)-hacking in Correlation Tables
The use of correlation tables is widespread in the literature, and they are a great tool for descriptive analysis but do not test your hypotheses with correlation tables. A good practice is to remove all \(p\)-values or \(p\)-stars from them.
\(p\)-values should only be produced to test an hypothesis that has been already formulated, any other is use is called \(p\)-hacking.
![]()
Interaction Effect Example
Variables
- Outcome = \(js\_score\) (from 0 to 10)
- Predictor 1 = \(salary\) (from 0 to Inf.)
- Predictor 2 = \(perf\) (from 0 to 10)
Hypotheses
- \(H_{a_{1}}\): \(js\_score\) increases when \(salary\) increases (i.e., \(b_1>0\))
- \(H_{0_{1}}\): \(js\_score\) stay the same when \(salary\) increases (i.e., \(b_1=0\))
- \(H_{a_{2}}\): \(js\_score\) increases when \(perf\) increases (i.e., \(b_2>0\))
- \(H_{0_{2}}\): \(js\_score\) stay the same when \(perf\) increases (i.e., \(b_2=0\))
- \(H_{a_{3}}\): The effect of \(salary\) on \(js\_score\) increases when \(perf\) increases (i.e., \(b_3>0\))
- \(H_{0_{3}}\): The effect of \(salary\) on \(js\_score\) is the same when \(perf\) increases (i.e., \(b_3=0\))
Interaction Effect Example
Equation
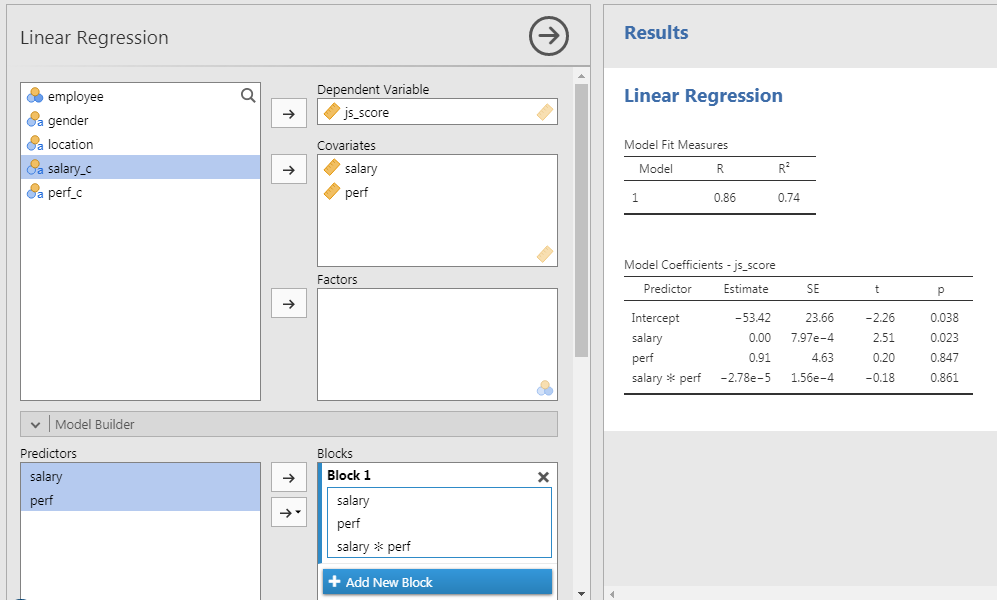
\[js\_score = b_{0} + b_{1}\,salary + b_{2}\,perf + b_{3}\,salary*perf + e\]
Note: The test of the interaction \(b_{3}\,salary*perf\) corresponds to the test of a new variable for which values of \(salary\) and values of \(perf\) are multiplied
![]()
Interaction Effect Example
In JAMOVI
- Open your file
- Set variables as continuous
- Analyses > Regression > Linear Regression
- Set \(js\_score\) as DV and \(salary\) as well as \(perf\) as Covariates
- In Model Builder option:
- Select both \(salary\) and \(perf\) to bring them in the covariates at once and to obtain a third term called \(salary*perf\)
Communicate Results
Overall model:
The prediction provided by the model with all predictors is significantly better than a model without predictors (\(R^2 = .74\), \(F(3, 16) = 15.20\), \(p < .001\)).
Salary Hypothesis:
The effect of \(salary\) on \(js\_score\) is statistically significant, therefore \(H_{0_{1}}\) can be rejected (\(b = 0.00\), 95% CI \([0.00, 0.00]\), \(t(16) = 2.51\), \(p = .023\)).
Perf Hypothesis:
The effect of \(perf\) on \(js\_score\) is not statistically significant, therefore \(H_{0_{2}}\) can’t be rejected (\(b = 0.91\), 95% CI \([-8.91, 10.72]\), \(t(16) = 0.20\), \(p = .847\)).
Interaction Hypothesis:
The interaction effect is not statistically significant, therefore \(H_{0_{3}}\) can’t be rejected (\(b = 0.00\), 95% CI \([0.00, 0.00]\), \(t(16) = -0.18\), \(p = .861\)).
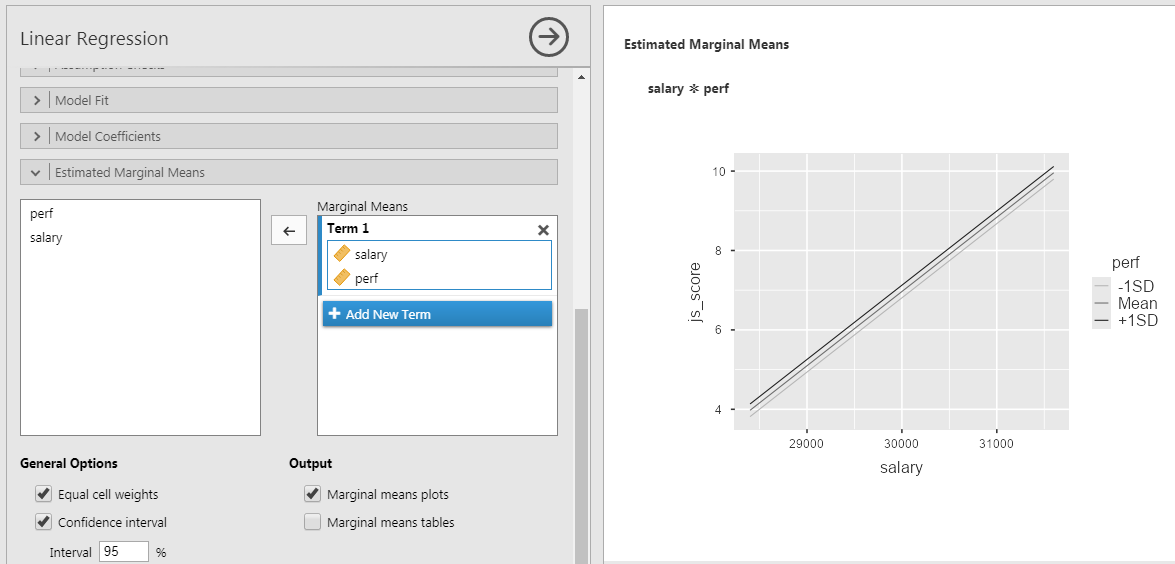
Representing Interaction Effects
- Go to Estimated Marginal Means
- Tick Marginal Means plot
- Select both predictor and bring them in Marginal Mean box at once
To plot the interaction between 2 continuous predictors, one of them has to be transform into categorical ordinal variable of 3 groups: +1SD, Mean, -1SD.
Representing Interaction Effects
In this case:
- +1SD is the group of high perf (observations > avg. + 1SD)
- Mean is the group of average perf (observations between avg. + 1SD and avg. - 1SD)
- -1SD is the group of low perf (observations < avg. - 1SD)
When representing the results of the linear regression don’t use the QQ-plot instead
\(salary*perf\) is a two-way interaction but interactions can three-, four-, n-way such as \(salary*perf*gender\) or \(salary*perf*gender*age\). However the more complex the interaction, the more difficult to interpret its effect.
️ Your Turn!
Open the file organisation_beta.csv in JAMOVI and …
- Reproduce the results obtained by testing the following models:
- \(js\_score = b_{0} + b_{1}\,salary + e\)
- \(js\_score = b_{0} + b_{1}\,salary + b_{2}\,perf + b_{3}\,salary*perf + e\)
- Test the following models:
\[js\_score = b_{0} + b_{1}\,gender + b_{2}\,perf + b_{3}\,gender*perf + e\]
\[js\_score = b_{0} + b_{1}\,location + b_{2}\,perf + b_{3}\,location*perf + e\]
️ Your Turn!
With the simulated data which uses the variables of your reference paper, test the model and the hypotheses that you have formulated in the previous homework exercises.
Communicate the results and send them to me before the next lecture.
Thanks for your attention
and don’t hesitate to ask if you have any questions!
![]()